Introduction
RIOT is a command-line utility to get data in and out of Redis. It supports any Redis-compatible database like Redis Cloud, Redis Community Edition, Redis Software.
RIOT includes the following features:
- Files (CSV, JSON, XML)
- Databases
- Data Generators
-
-
Redis Data Generator: Data Structures → Redis
-
Faker Data Generator: Faker → Redis
-
- Replication
-
Redis → Redis
RIOT is supported by Redis, Inc. on a good faith effort basis. To report bugs, request features, or receive assistance, please file an issue or contact your Redis account team.
RIOT-X
RIOT-X is an extension to RIOT which provides the following additional features for Redis Cloud and Redis Software:
-
Observability
-
Memcached Replication
-
Stream Import/Export
Full documentation for RIOT-X is available here: redis-field-engineering.github.io/riotx
Install
RIOT can be installed on Linux, macOS, and Windows platforms and can be used as a standalone tool that connects remotely to a Redis database. It is not required to run locally on a Redis server.
Homebrew (macOS & Linux)
brew install redis/tap/riotScoop (Windows)
scoop bucket add redis https://github.com/redis/scoop.git
scoop install riotManual Installation (All Platforms)
Download the pre-compiled binary from RIOT Releases, uncompress and copy to the desired location.
|
|
Docker
You can run RIOT as a docker image:
docker run riotx/riot [OPTIONS] [COMMAND]Concepts
RIOT is essentially an ETL tool where data is extracted from the source system, transformed (see Processing), and loaded into the target system.

Redis URI
RIOT follows the Redis URI specification, which supports standalone, sentinel and cluster Redis deployments with plain, SSL, TLS and unix domain socket connections.
You can use the host:port short hand for redis://host:port.
|
- Redis Standalone
-
redis :// [[username :] password@] host [:port][/database] [?[timeout=timeout[d|h|m|s|ms|us|ns]] [&clientName=clientName] [&libraryName=libraryName] [&libraryVersion=libraryVersion] ] - Redis Standalone (SSL)
-
rediss :// [[username :] password@] host [: port][/database] [?[timeout=timeout[d|h|m|s|ms|us|ns]] [&clientName=clientName] [&libraryName=libraryName] [&libraryVersion=libraryVersion] ] - Redis Sentinel
-
redis-sentinel :// [[username :] password@] host1[:port1] [, host2[:port2]] [, hostN[:portN]] [/database] [?[timeout=timeout[d|h|m|s|ms|us|ns]] [&sentinelMasterId=sentinelMasterId] [&clientName=clientName] [&libraryName=libraryName] [&libraryVersion=libraryVersion] ]
You can provide the database, password and timeouts within the Redis URI. For example redis://localhost:6379/1 selects database 1.
|
d
|
Days |
h
|
Hours |
m
|
Minutes |
s
|
Seconds |
ms
|
Milliseconds |
us
|
Microseconds |
ns
|
Nanoseconds |
Batching
Processing in RIOT is done in batches: a fixed number of records is read from the source, processed, and written to the target.
The default batch size is 50, which means that an execution step reads 50 items at a time from the source, processes them, and finally writes then to the target.
If the source/target is Redis, reading/writing of a batch is done in a single command pipeline to minimize the number of roundtrips to the server.
You can change the batch size (and hence pipeline size) using the --batch option.
The optimal batch size in terms of throughput depends on many factors like record size and command types (see Redis Pipeline Tuning for details).
Multi-threading
By default processing happens in a single thread, but it is possible to parallelize processing by using multiple threads. In that configuration, each chunk of items is read, processed, and written in a separate thread of execution. This is different from partitioning where items would be read by multiple readers. Here, only one reader is being accessed from multiple threads.
To set the number of threads, use the --threads option.
riot db-import "SELECT * FROM orders" --jdbc-url "jdbc:postgresql://host:port/database" --jdbc-user appuser --jdbc-pass passwd --threads 3 hset --keyspace order --key order_idImporting
When importing data into Redis (file-import, db-import, faker) the following options allow for field-level processing and filtering.
Processing
Processors allow you to create/update/delete fields using the Spring Expression Language (SpEL).
--proc field1="'foo'"-
Generate a field named
field1containing the stringfoo --proc temp="(temp-32)*5/9"-
Convert from Fahrenheit to Celsius
--proc name='remove("first").concat(remove("last"))'-
Concatenate
firstandlastfields and delete them --proc field2=null-
Delete
field2
Input fields are accessed by name (e.g. field3=field1+field2).
Processors have access to the following context variables and functions:
date-
Date parsing and formatting object. Instance of Java SimpleDateFormat.
number-
Number parsing and formatting object. Instance of Java DecimalFormat.
faker-
Faker object.
redis-
Redis commands object. Instance of Lettuce RedisCommands. The
replicatecommand exposes 2 command objects namedsourceandtarget. geo-
Convenience function that takes a longitude and a latitude to produce a RediSearch geo-location string in the form
longitude,latitude(e.g.location=#geo(lon,lat))
riot file-import --proc epoch="#date.parse(mydate).getTime()" location="#geo(lon,lat)" name="#redis.hget('person1','lastName')" ...riot file-import http://storage.googleapis.com/jrx/beers.csv --header --proc fakeid="#faker.numerify('########')" hset --keyspace beer --key fakeidYou can register your own variables using --var.
riot file-import http://storage.googleapis.com/jrx/lacity.csv --var rnd="new java.util.Random()" --proc randomInt="#rnd.nextInt(100)" --header hset --keyspace event --key IdFiltering
Filters allow you to exclude records that don’t match a SpEL boolean expression.
For example this filter will only keep records where the value field is a series of digits:
riot file-import --filter "value matches '\\d+'" ...Exporting
When exporting data from Redis the following options allow for filtering .
Key Filtering
Key filtering can be done through multiple options in RIOT:
--key-pattern-
Glob-style pattern used for scan and keyspace notification registration.
--key-type-
Type of keys to consider for scan and keyspace notification registration.
--key-include&--key-exclude-
Glob-style pattern(s) to futher filter keys on the client (RIOT) side, i.e. after they are received through scan or keyspace notifications.
--mem-limit: Ignore keys whose memory usage exceeds the given limit. For example --mem-limit 10mb skips keys over 10 MB in size.
Usage
You can launch RIOT with the following command:
riotThis will show usage help, which you can also get by running:
riot --help--help is available on any command:
riot COMMAND --help|
Run the following command to give |
Data Generation
RIOT includes 2 commands for data generation:
Data Structure Generator
The gen command generates Redis data structures as well as JSON and Timeseries.
riot gen [OPTIONS]riot gen --type string hash json timeseriesFaker Generator
The faker command generates data using Datafaker.
riot faker [OPTIONS] EXPRESSION... [REDIS COMMAND...]where EXPRESSION is a Faker expression field in the form field="expression".
To show the full usage, run:
riot faker --helpYou must specify at least one Redis command as a target.
|
Redis connection options apply to the root command ( In this example the Redis options will not be taken into account: |
Keys
Keys are constructed from input records by concatenating the keyspace prefix and key fields.

riot faker id="numerify '##########'" firstName="name.first_name" lastName="name.last_name" address="address.full_address" hset --keyspace person --key idriot faker name="GameOfThrones.character" --count 1000 sadd --keyspace got:characters --member nameData Providers
Faker offers many data providers. Most providers don’t take any arguments and can be called directly:
riot faker firstName="name.first_name"Some providers take parameters:
riot faker lease="number.digits '2'"Here are a few sample Faker expressions:
-
regexify '(a|b){2,3}' -
regexify '\\.\\*\\?\\+' -
bothify '????','false' -
name.first_name -
name.last_name -
number.number_between '1','10'
Refer to Datafaker Providers for a list of providers and their corresponding documentation.
Databases
RIOT includes two commands for interaction with relational databases:
Drivers
RIOT relies on JDBC to interact with databases. It includes JDBC drivers for the most common database systems:
- Oracle
-
jdbc:oracle:thin:@myhost:1521:orcl - SQL Server
-
jdbc:sqlserver://[serverName[\instanceName][:portNumber]][;property=value[;property=value]] - MySQL
-
jdbc:mysql://[host]:[port][/database][?properties] - Postgres
-
jdbc:postgresql://host:port/database
|
For non-included databases you must install the corresponding JDBC driver under the
|
Database Import
The db-import command imports data from a relational database into Redis.
| Ensure RIOT has the relevant JDBC driver for your database. See the Drivers section for more details. |
riot db-import --jdbc-url <jdbc url> -u <Redis URI> SQL [REDIS COMMAND...]To show the full usage, run:
riot db-import --helpYou must specify at least one Redis command as a target.
Redis connection options apply to the root command (riot) and not to subcommands.
|
The keys that will be written are constructed from input records by concatenating the keyspace prefix and key fields.
riot db-import "SELECT * FROM orders" --jdbc-url "jdbc:postgresql://host:port/database" --jdbc-user appuser --jdbc-pass passwd hset --keyspace order --key order_idriot db-import "SELECT * FROM orders" --jdbc-url "jdbc:postgresql://host:port/database" --jdbc-user appuser --jdbc-pass passwd set --keyspace order --key order_idThis will produce Redis strings that look like this:
{
"order_id": 10248,
"customer_id": "VINET",
"employee_id": 5,
"order_date": "1996-07-04",
"required_date": "1996-08-01",
"shipped_date": "1996-07-16",
"ship_via": 3,
"freight": 32.38,
"ship_name": "Vins et alcools Chevalier",
"ship_address": "59 rue de l'Abbaye",
"ship_city": "Reims",
"ship_postal_code": "51100",
"ship_country": "France"
}Database Export
Use the db-export command to read from a Redis database and writes to a SQL database.
| Ensure RIOT has the relevant JDBC driver for your database. See the Drivers section for more details. |
The general usage is:
riot db-export --jdbc-url <jdbc url> SQLTo show the full usage, run:
riot db-export --helpriot db-export "INSERT INTO mytable (id, field1, field2) VALUES (CAST(:id AS SMALLINT), :field1, :field2)" --jdbc-url "jdbc:postgresql://host:port/database" --jdbc-user appuser --jdbc-pass passwd --key-pattern "gen:*" --key-regex "gen:(?<id>.*)"Files
RIOT includes two commands to work with files in various formats:
file-import-
Import data from files
file-export-
Export Redis data structures to files
File Import
The file-import command reads data from files and writes it to Redis.
The basic usage for file imports is:
riot file-import [OPTIONS] FILE... [REDIS COMMAND...]To show the full usage, run:
riot file-import --helpRIOT will try to determine the file type from its extension (e.g. .csv or .json), but you can specify it with the --type option.
Gzipped files are supported and the extension before .gz is used (e.g. myfile.json.gz → json).
-
/path/file.csv -
/path/file-*.csv -
/path/file.json -
http://data.com/file.csv -
http://data.com/file.json.gz
Use - to read from standard input.
|
Amazon S3 and Google Cloud Storage buckets are supported.
riot file-import s3://riotx/beers.json --s3-region us-west-1 hset --keyspace beer --key idriot file-import gs://riotx/beers.json hset --keyspace beer --key idData Structures
If no REDIS COMMAND is specified, it is assumed that the input file(s) contain Redis data structures serialized as JSON or XML. See the File Export section to learn about the expected format and how to generate such files.
riot file-import /tmp/redis.jsonRedis Commands
When one or more `REDIS COMMAND`s are specified, these commands are called for each input record.
|
Redis client options apply to the root command ( In this example Redis client options will not be taken into account: |
Redis command keys are constructed from input records by concatenating keyspace prefix and key fields.
blah:<id>riot file-import my.json hset --keyspace blah --key idriot file-import http://storage.googleapis.com/jrx/es_test-index.json json.set --keyspace elastic --key _idriot file-import my.json hset --keyspace blah --key id expire --keyspace blah --key idblah:<id> and set TTL and add each id to a set named mysetriot file-import my.json hset --keyspace blah --key id expire --keyspace blah --key id sadd --keyspace myset --member idDelimited (CSV)
The default delimiter character is comma (,).
It can be changed with the --delimiter option.
If the file has a header, use the --header option to automatically extract field names.
Otherwise specify the field names using the --fields option.
Let’s consider this CSV file:
| row | abv | ibu | id | name | style | brewery | ounces |
|---|---|---|---|---|---|---|---|
1 |
0.079 |
45 |
321 |
Fireside Chat (2010) |
Winter Warmer |
368 |
12.0 |
2 |
0.068 |
65 |
173 |
Back in Black |
American Black Ale |
368 |
12.0 |
3 |
0.083 |
35 |
11 |
Monk’s Blood |
Belgian Dark Ale |
368 |
12.0 |
The following command imports this CSV into Redis as hashes using beer as the key prefix and id as primary key.
riot file-import http://storage.googleapis.com/jrx/beers.csv --header hset --keyspace beer --key idThis creates hashes with keys beer:321, beer:173, …
This command imports a CSV file into a geo set named airportgeo with airport IDs as members:
riot file-import http://storage.googleapis.com/jrx/airports.csv --header --skip-limit 3 geoadd --keyspace airportgeo --member AirportID --lon Longitude --lat LatitudeFixed-Length (Fixed-Width)
Fixed-length files can be imported by specifying the width of each field using the --ranges option.
riot file-import http://storage.googleapis.com/jrx/accounts.fw --type fw --ranges 1 9 25 41 53 67 83 --header hset --keyspace account --key AccountJSON
The expected format for JSON files is:
[
{
"...": "..."
},
{
"...": "..."
}
]riot file-import /tmp/redis.jsonJSON records are trees with potentially nested values that need to be flattened when the target is a Redis hash for example.
To that end, RIOT uses a field naming convention to flatten JSON objects and arrays:
|
→ |
|
|
→ |
|
XML
Here is a sample XML file that can be imported by RIOT:
<?xml version="1.0" encoding="UTF-8"?>
<records>
<trade>
<isin>XYZ0001</isin>
<quantity>5</quantity>
<price>11.39</price>
<customer>Customer1</customer>
</trade>
<trade>
<isin>XYZ0002</isin>
<quantity>2</quantity>
<price>72.99</price>
<customer>Customer2c</customer>
</trade>
<trade>
<isin>XYZ0003</isin>
<quantity>9</quantity>
<price>99.99</price>
<customer>Customer3</customer>
</trade>
</records>riot file-import http://storage.googleapis.com/jrx/trades.xml hset --keyspace trade --key idFile Export
The file-export command reads data from a Redis database and writes it to a JSON or XML file, potentially gzip-compressed.
The general usage is:
riot file-export [OPTIONS] FILETo show the full usage, run:
riot file-export --helpJSON
riot file-export /tmp/redis.json[
{
"key": "string:615",
"ttl": -1,
"value": "value:615",
"type": "STRING"
},
{
"key": "hash:511",
"ttl": -1,
"value": {
"field1": "value511",
"field2": "value511"
},
"type": "HASH"
},
{
"key": "list:1",
"ttl": -1,
"value": [
"member:991",
"member:981"
],
"type": "LIST"
},
{
"key": "set:2",
"ttl": -1,
"value": [
"member:2",
"member:3"
],
"type": "SET"
},
{
"key": "zset:0",
"ttl": -1,
"value": [
{
"value": "member:1",
"score": 1.0
}
],
"type": "ZSET"
},
{
"key": "stream:0",
"ttl": -1,
"value": [
{
"stream": "stream:0",
"id": "1602190921109-0",
"body": {
"field1": "value0",
"field2": "value0"
}
}
],
"type": "STREAM"
}
]riot file-export /tmp/beers.json.gz --key-pattern beer:*Replication
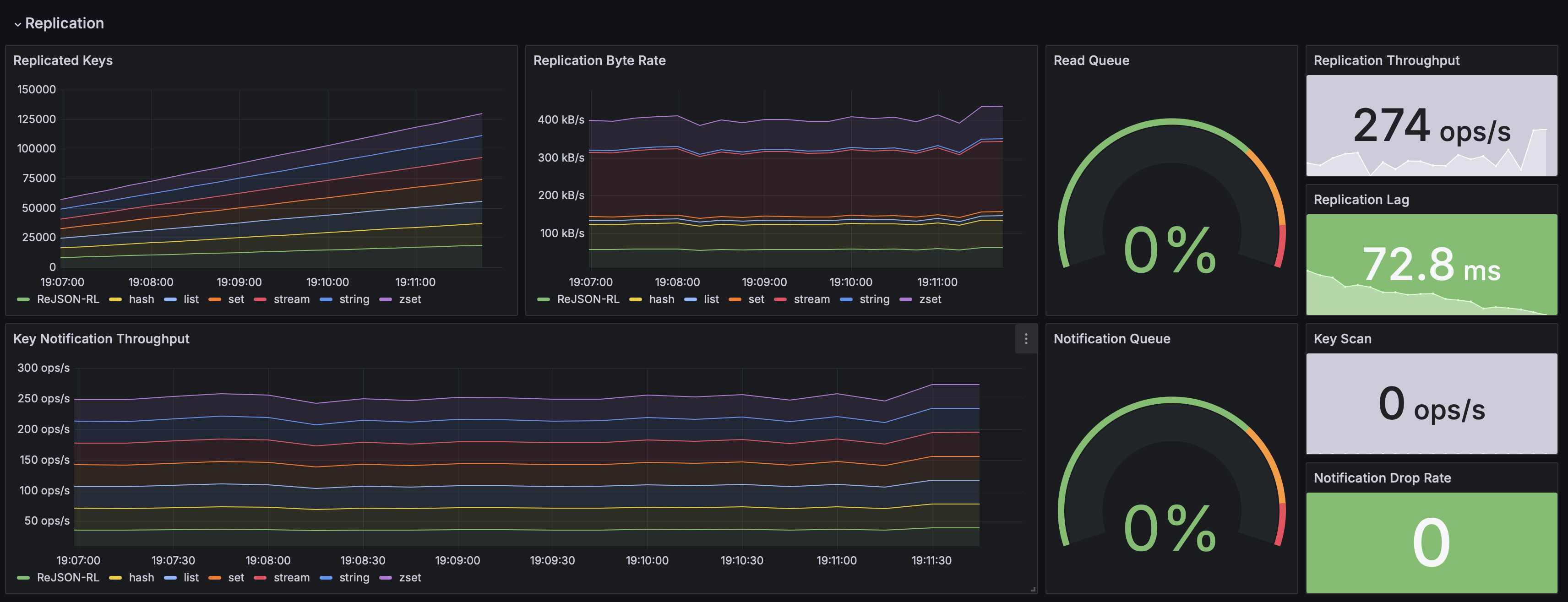
The replicate command reads data from a source Redis database and writes to a target Redis database.

The replication mechanism is as follows:
-
Identify source keys to be replicated using scan and/or keyspace notifications depending on the replication mode.
-
Read data associated with each key using dump or type-specific commands.
-
Write each key to the target using restore or type-specific commands.
The basic usage is:
riot replicate [OPTIONS] SOURCE TARGETwhere SOURCE and TARGET are Redis URIs.
For the full usage, run:
riot replicate --help
To replicate a Redis logical database other than the default (0), specify the database in the source Redis URI.
For example riot replicate redis://source:6379/1 redis://target:6379 replicates database 1.
|
Replication Mode
Replication starts with identifying keys to be replicated from the source Redis database.
The --mode option allows you to specify how RIOT identifies keys to be replicated:
-
iterate over keys with a key scan (
--mode scan) -
received by a keyspace notification subscriber (
--mode liveonly) -
or both (
--mode live)
Scan
This key reader scans for keys using the Redis SCAN command:
SCAN cursor [MATCH pattern] [COUNT count] [TYPE type]MATCH pattern-
configured with the
--key-patternoption TYPE type-
configured with the
--key-typeoption COUNT count-
configured with the
--scan-countoption
INFO: In cluster mode keys are scanned in parallel across cluster nodes.
The status bar shows progress with a percentage of keys that have been replicated. The total number of keys is estimated when the replication process starts and it can change by the time it is finished, for example if keys are deleted or added during replication.
riot replicate redis://source redis://targetLive
The key notification reader listens for key changes using keyspace notifications.
Make sure the source database has keyspace notifications enabled using:
-
redis.conf:notify-keyspace-events = KEA -
CONFIG SET notify-keyspace-events KEA
For more details see Redis Keyspace Notifications.
riot replicate --mode live redis://source redis://target|
The live replication mechanism does not guarantee data consistency. Redis sends keyspace notifications over pub/sub which does not provide guaranteed delivery. It is possible that RIOT can miss some notifications in case of network failures for example. Also, depending on the type, size, and rate of change of data structures on the source it is possible that RIOT cannot keep up with the change stream. For example if a big set is repeatedly updated, RIOT will need to read the whole set on each update and transfer it over to the target database. With a big-enough set, RIOT could fall behind and the internal queue could fill up leading up to updates being dropped. For those potentially problematic migrations it is recommend to perform some preliminary sizing using Redis statistics and |
Replication Types
RIOT offers two different mechanisms for reading and writing keys:
-
Dump & restore (default)
-
Data structure replication (
--struct)
Dump & Restore
The default replication mechanism is Dump & Restore:
-
Scan for keys in the source Redis database. If live replication is enabled the reader also subscribes to keyspace notifications to generate a continuous stream of keys.
-
Reader threads iterate over the keys to read corresponding values (DUMP) and TTLs.
-
Reader threads enqueue key/value/TTL tuples into the reader queue, from which the writer dequeues key/value/TTL tuples and writes them to the target Redis database by calling RESTORE and EXPIRE.
Data Structure Replication
There are situations where Dump & Restore cannot be used, for example:
-
The target Redis database does not support the RESTORE command (Redis Enterprise CRDB)
-
Incompatible DUMP formats between source and target (Redis 7.0)
In those cases you can use another replication strategy that is data structure-specific: each key is introspected to determine its type and then use the corresponding read/write commands.
| Type | Read | Write |
|---|---|---|
Hash |
|
|
JSON |
|
|
List |
|
|
Set |
|
|
Sorted Set |
|
|
Stream |
|
|
String |
|
|
TimeSeries |
|
|
| This replication strategy is more intensive in terms of CPU, memory, and network for all the machines involved (source Redis, target Redis, and RIOT machines). Adjust number of threads, batch and queue sizes accordingly. |
riot replicate --struct redis://source redis://targetriot replicate --struct --mode live redis://source redis://targetCompare
Once replication is complete, RIOT performs a verification step by reading keys in the source database and comparing them against the target database.
The verification step happens automatically after the scan is complete (snapshot replication), or for live replication when keyspace notifications have become idle.
Verification can also be run on-demand using the compare command:
riot compare SOURCE TARGET [OPTIONS]The output looks like this:
Verification failed (type: 225,062, missing: 485,450)
- missing
-
Number of keys in source but not in target.
- type
-
Number of keys with mismatched types (e.g. hash vs string).
- value
-
Number of keys with mismatched values.
- ttl
-
Number of keys with mismatched TTL i.e. difference is greater than tolerance (can be specified with
--ttl-tolerance).
There are 2 comparison modes available through --compare (--quick for compare command):
- Quick (default)
-
Compare key types and TTLs.
- Full
-
Compare key types, TTLs, and values.
To show which keys differ, use the --show-diffs option.
Performance
Performance tuning is an art but RIOT offers some options to identify potential bottlenecks.
In addition to --batch and --threads options you have the --dry-run option which disables writing to the target Redis database so that you can tune the reader in isolation.
Add that option to your existing replicate command-line to compare replication speeds with and without writing to the target Redis database.
Cookbook
Here are various recipes using RIOT.
Changelog
You can use RIOT to stream change data from a Redis database.
riot file-export --mode live
{"key":"gen:1","type":"string","time":1718050552000,"ttl":-1,"memoryUsage":300003376}
{"key":"gen:3","type":"string","time":1718050552000,"ttl":-1,"memoryUsage":300003376}
{"key":"gen:6","type":"string","time":1718050552000,"ttl":-1,"memoryUsage":300003376}
...riot file-export export.json --mode liveElastiCache Migration
This recipe contains step-by-step instructions to migrate an ElastiCache (EC) database to Redis Cloud or Redis Software.
The following scenarios are covered:
-
One-time (snapshot) migration
-
Online (live) migration
| It is recommended to read the Replication section to familiarize yourself with its usage and architecture. |
Setup
Prerequisites
For this recipe you will require the following resources:
-
AWS ElastiCache: Primary Endpoint in case of Single Master and Configuration Endpoint in case of Clustered EC. Refer to this link to learn more
-
An Amazon EC2 instance to run RIOT
|
Keyspace Notifications
For a live migration you need to enable keyspace notifications on your ElastiCache instance (see AWS Knowledge Center). |
Migration Host
To run the migration tool we will need an EC2 instance.
You can either create a new EC2 instance or leverage an existing one if available. In the example below we first create an instance on AWS Cloud Platform. The most common scenario is to access an ElastiCache cluster from an Amazon EC2 instance in the same Amazon Virtual Private Cloud (Amazon VPC). We have used Ubuntu 16.04 LTS for this setup but you can choose any Ubuntu or Debian distribution of your choice.
SSH to this EC2 instance from your laptop:
ssh -i “public key” <AWS EC2 Instance>Install redis-cli on this new instance by running this command:
sudo apt update
sudo apt install -y redis-toolsUse redis-cli to check connectivity with the ElastiCache database:
redis-cli -h <ec primary endpoint> -p 6379Ensure that the above command allows you to connect to the remote ElastiCache database successfully.
Installing RIOT
Let’s install RIOT on the EC2 instance we set up previously. For this we’ll follow the steps in Manual Installation.
Performing Migration
We are now all set to begin the migration process. The options you will use depend on your source and target databases, as well as the replication mode (snapshot or live).
Live ElastiCache Single Master → Redis
riot replicate source:port target:port --mode live|
In case ElastiCache is configured with AUTH TOKEN enabled, you need to pass |
ElastiCache Cluster → Redis
riot replicate source:port target:port --source-cluster
--cluster is an important parameter used ONLY for ElastiCache whenever cluster-mode is enabled.
Do note that the source database is specified first and the target database is specified after the replicate command and it is applicable for all the scenarios.
|
ElastiCache Single Master → Redis (with specific database index)
riot replicate redis://source:port/db target:portImportant Considerations
-
It is recommended to test migration in UAT before production use.
-
Once migration is completed, ensure that application traffic gets redirected to Redis endpoint successfully.
-
It is recommended to perform the migration process during low traffic hours so as to avoid chances of data loss.
Connectivity Test
The ping command can be used to test connectivity to a Redis database.
riot ping [OPTIONS]To show the full usage, run:
riot ping --helpThe command prints statistics like these:
riot ping -h localhost --unit microseconds
[min=491, max=14811, percentiles={99.9=14811, 90.0=1376, 95.0=2179, 99.0=14811, 50.0=741}]
[min=417, max=1286, percentiles={99.9=1286, 90.0=880, 95.0=1097, 99.0=1286, 50.0=606}]
[min=382, max=2244, percentiles={99.9=2244, 90.0=811, 95.0=1036, 99.0=2244, 50.0=518}]
...FAQ
-
Logs are cut off or missing
This could be due to concurrency issues in the terminal when refreshing the progress bar and displaying logs. Try running with job option
--progress log. -
Unknown options: '--keyspace', '--key'
You must specify one or more Redis commands with import commands (
file-import,faker,db-import). -
ERR DUMP payload version or checksum are wrong
Redis 7 DUMP format is not backwards compatible with previous versions. To replicate between different Redis versions, use Type-Based Replication.
-
ERR Unsupported Type 0
The target database is most likely CRDB in which case you need to use type-based replication (
--structoption). -
Process gets stuck during replication and eventually times out
This could be due to big keys clogging the replication pipes. In these cases it might be hard to catch the offending key(s). Try running the same command with
--infoand--progress logso that all errors are reported. Check the database withredis-cliBig keys and/or use reader options to filter these keys out. -
NOAUTH Authentication required
This issue occurs when you fail to supply the
--pass <password>parameter. -
ERR The ID argument cannot be a complete ID because xadd-id-uniqueness-mode is strict
This usually happens in Active/Active (CRDB) setups where stream message IDs cannot be copied over to the target database. Use the
--no-stream-idoption to disable ID propagation. -
ERR Error running script… This Redis command is not allowed from scripts
This can happen with Active/Active (CRDB) databases because the
MEMORY USAGEcommand is not allowed to be run from a LUA script. Use the--mem-limit -1option to disable memory usage. -
java.lang.OutOfMemoryError: Java heap space
The RIOT JVM ran out of memory. Either increase max JVM heap size (
export JAVA_OPTS="-Xmx8g") or reduce RIOT memory usage by loweringthreads,batch,read-batchandread-queue.